
How to Build a Document-Based Q&A System in FlowiseAI

Building a document-based Q&A system is easier with the right tools. Open-source solutions like FlowiseAI and Qdrant enable efficient retrieval and AI-powered responses. This blog covers how to set up a system using FlowiseAI for automation, Qdrant as a vector database, and OpenAI embeddings for semantic search. From data collection to response generation, each step ensures accuracy and efficiency.
Workflow Overview
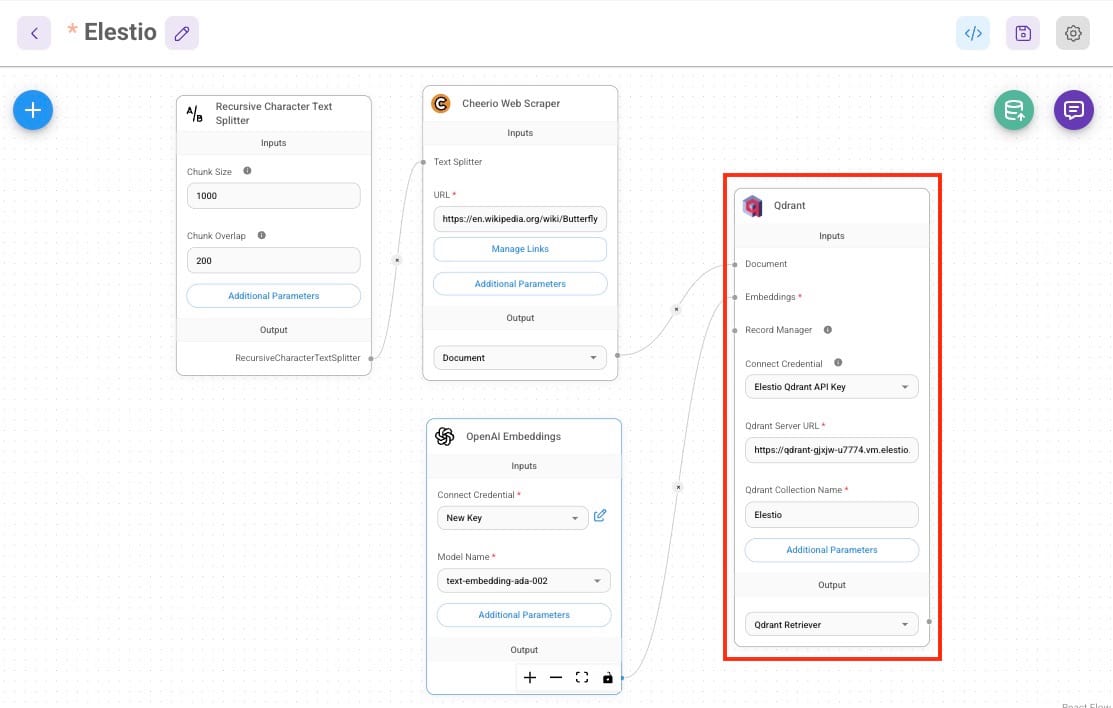
The following image represents the FlowiseAI workflow for this Q&A system:
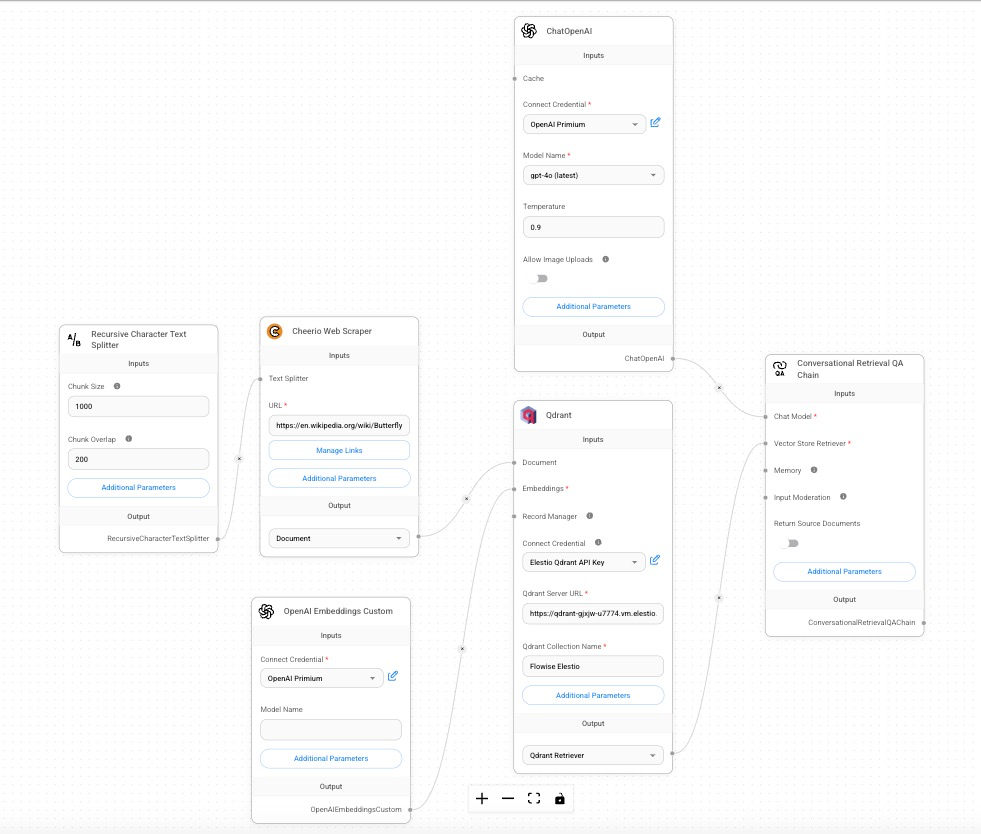
The workflow includes nodes for scraping text data, processing it into chunks, generating embeddings, storing the embeddings in a vector database, and finally generating AI-powered responses.
Collecting Data
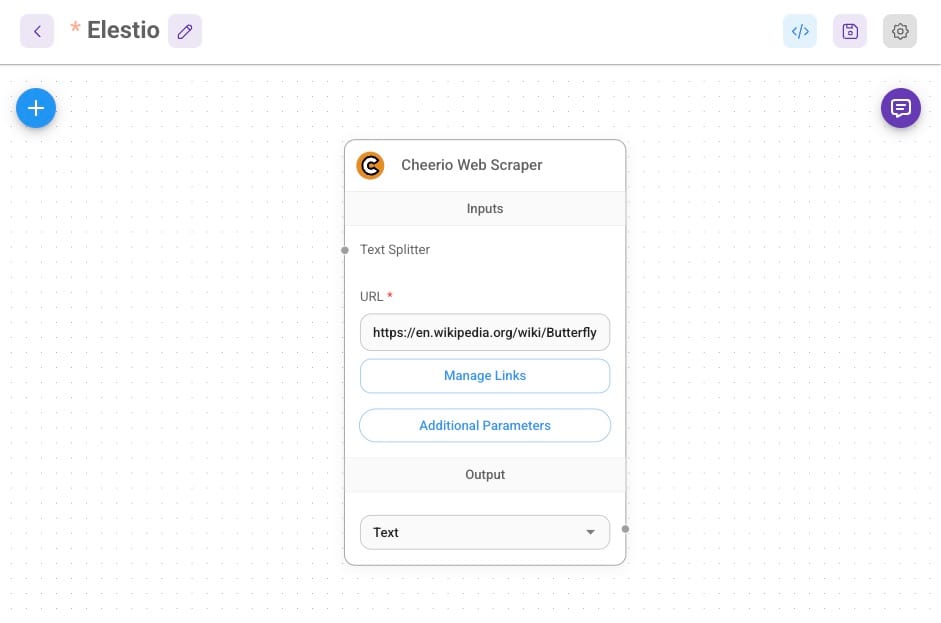
Cheerio is a lightweight library used for web scraping. It parses HTML and XML documents, enabling developers to query and manipulate elements with a syntax similar to jQuery. In FlowiseAI, the Cheerio Web Scraper node automates this process, extracting the raw textual content needed for further processing. To build a meaningful Q&A system, data is gathered from reliable sources. The Cheerio Web Scraper node plays a crucial role in this process by extracting content directly from the specified website URL. For this project, the scraper is configured to target Wikipedia’s Butterfly page:https://en.wikipedia.org/wiki/Butterfly.
Additional documents such as PDFs or text files can be uploaded using the File Upload node to expand the knowledge base.
Preprocessing the Data
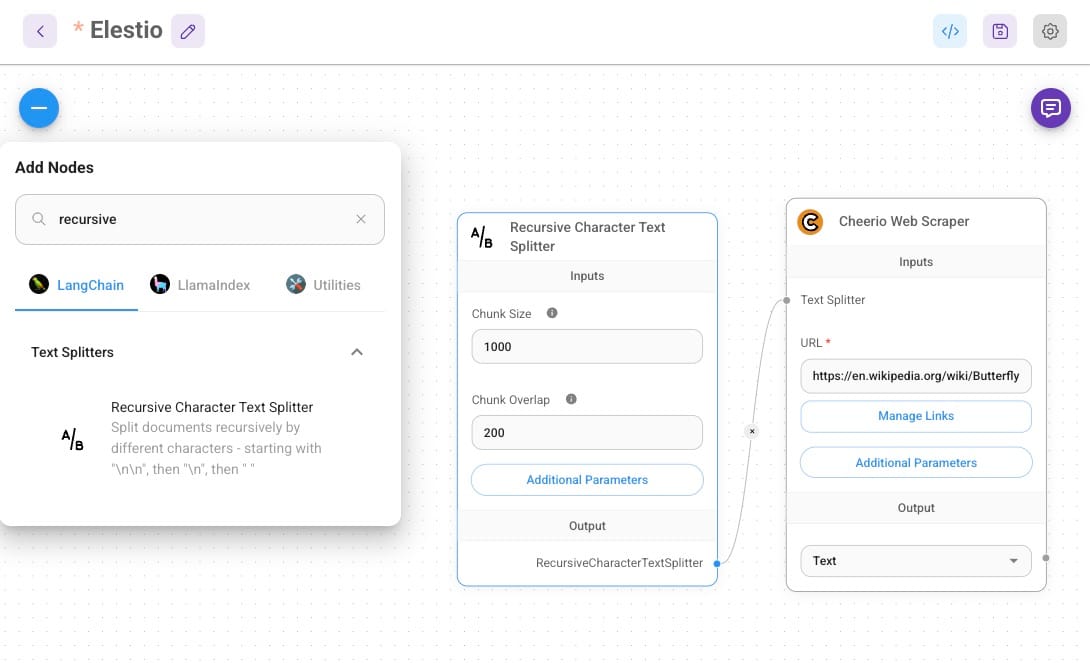
Once the data is scraped or uploaded, it needs to be preprocessed for efficient storage and retrieval. The Recursive Character Text Splitter node is used to break down large text blocks into manageable chunks. Some documents, especially those sourced from web scraping or file uploads, may contain long passages that exceed the token limit of AI models like GPT-4. Feeding such large chunks into the embedding or response generation pipeline could result in errors, inefficiencies, or incomplete answers.
Recursive splitting solves this problem by breaking the text into smaller, logical chunks. It prioritizes splitting at natural boundaries, such as sentences or paragraphs, while also allowing overlapping chunks. Overlap ensures that details near the edges of one chunk are retained in the next, preserving the context and enhancing retrieval accuracy.
In this Q&A system:
- The chunk size is set to 1000 characters, for a balance between context retention and processing efficiency.
- The chunk overlap is 200 characters, ensuring smooth transitions between chunks without information loss.
Preprocessing also involves stripping unnecessary formatting or HTML tags, ensuring clean and structured data for embedding.
Generating Embeddings
The preprocessed text chunks are converted into vector embeddings using the OpenAI Embeddings Custom node. These embeddings are created using OpenAI's text-embedding-ada-002 model, which is known for its ability to encode semantic meanings into numerical vectors.
Steps to Configuring OpenAI
- Open the OpenAI Embeddings Node:
In the FlowiseAI interface, locate and open the OpenAI Embeddings node in your workflow.
- Connect Credentials:
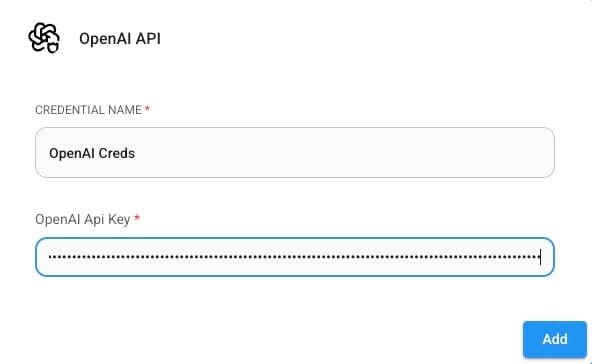
- Under the "Connect Credential" field, select OpenAI Creds from the dropdown.
- If no credentials are configured yet, To generate an API key, visit the OpenAI API Dashboard. Log in with your OpenAI account, navigate to the API Keys section, and click Create new secret key. Copy the generated key and paste it into the FlowiseAI credentials field. Save the configuration and select it from the dropdown. click the Manage Credentials option and enter your OpenAI API key. Save the configuration and select it from the dropdown.
- Model Selection:
- Choose
text-embedding-ada-002from the model list. This ensures the embeddings are generated using OpenAI's state-of-the-art embedding model.
- Choose
- Configure Additional Parameters (Optional):
- You can adjust additional parameters such as embedding batch size if required.
- Locate the Top K field and set the number of chunks you want to retrieve (e.g., 5 or 10). A higher value ensures a broader context but may include less relevant chunks, while a lower value narrows down the results for precision.
Storing and Retrieving Data
The embeddings are stored in Qdrant, a high-performance vector database designed for storing and querying embeddings. Qdrant’s indexing mechanisms and optimized similarity search capabilities make it ideal for this application. For this blog, we will be using Qdrant as a vector database which is hosted on Elestio. Head over to Elestio dashboard and grab the information available and we will require that in next steps.
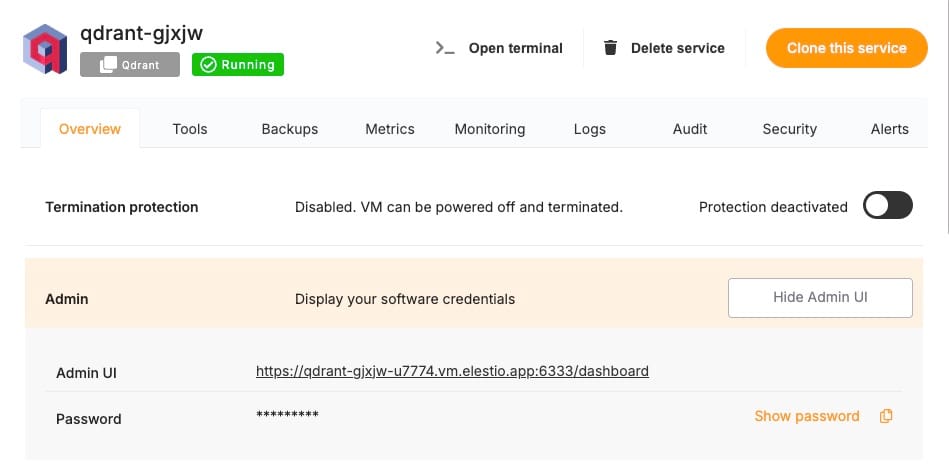
The Qdrant node in FlowiseAI connects to the Elestio-hosted server athttp://<elestio-dash-url>.vm.elestio.app. A collection named Flowise Elestio is created to store the embeddings. Each chunk, along with metadata, is stored in this collection for efficient retrieval. You can create this collection by using the scripts provided in the Qdrant documentation. Additionally if you have Additional API credential of QDrant then you can add them under Connection Credential.
Generating AI Responses
Once the relevant chunks are retrieved, they are formatted and passed as context to the ChatOpenAI node. Instead of relying on generic pre-trained knowledge, GPT-4o generates responses based on the retrieved data, ensuring accuracy and relevance. To optimize response quality, the temperature setting for the ChatOpenAI node is configured at 0.9, balancing factual accuracy with natural-sounding creativity. The input moderation feature filters out inappropriate or irrelevant queries, ensuring the system remains robust and user-friendly.
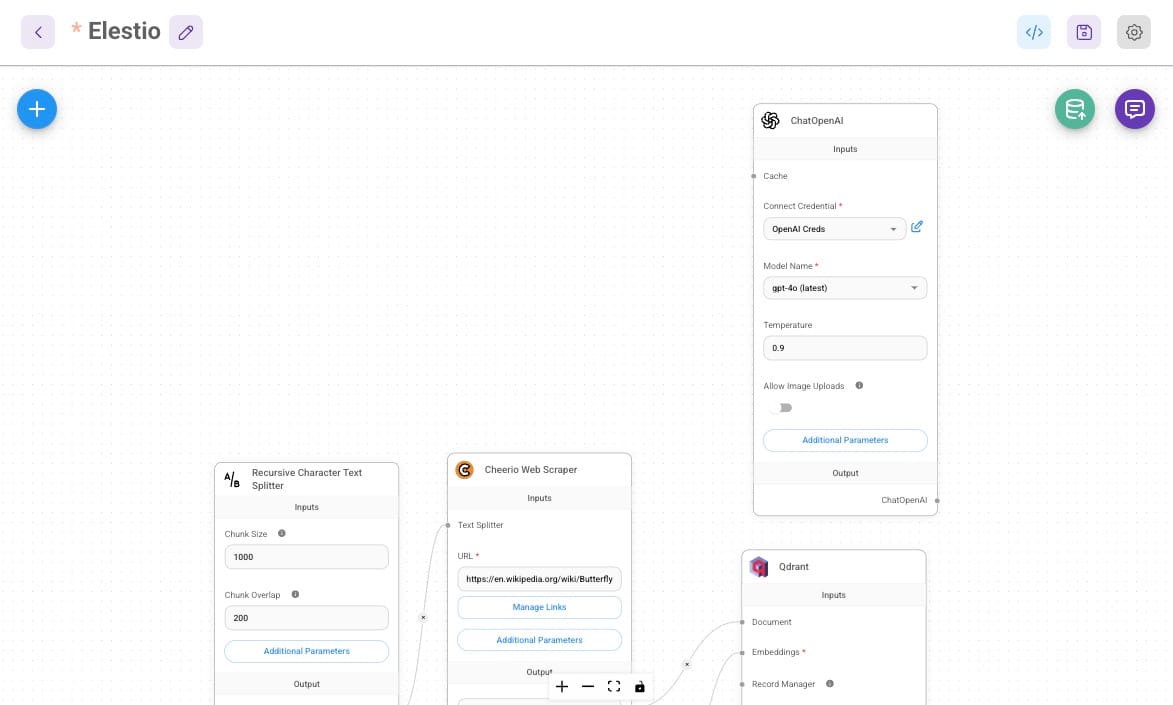
The Conversational Retrieval QA Chain maintains session history, allowing for multi-turn conversations where users can refine or build upon previous queries. By using the Conversational Retrieval QA Chain, this Q&A system ensures that responses are grounded in real-time, scraped, and processed documents, making it a powerful tool for document-based question answering.
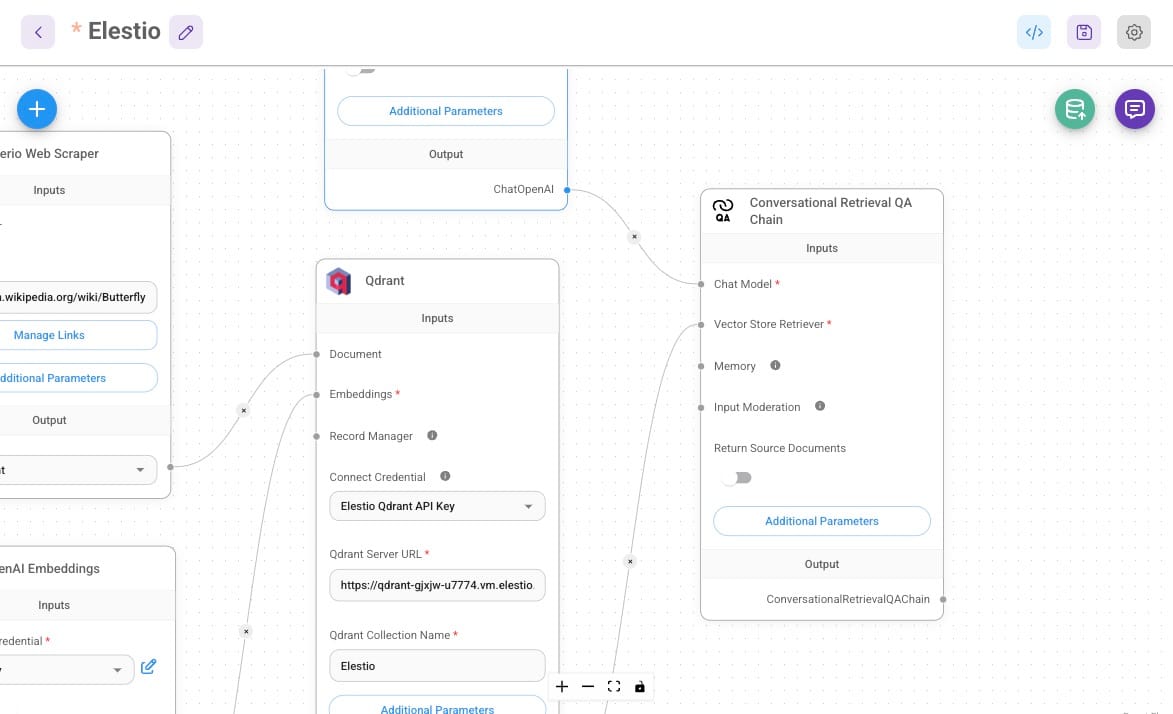
Testing and Optimization
To fine-tune the system’s performance, adjust the chunk size to balance context retention with efficiency. Experiment with retrieval settings like the number of top results to ensure the most relevant content is returned. Optimize the temperature parameter to control the creativity and factual accuracy of responses.
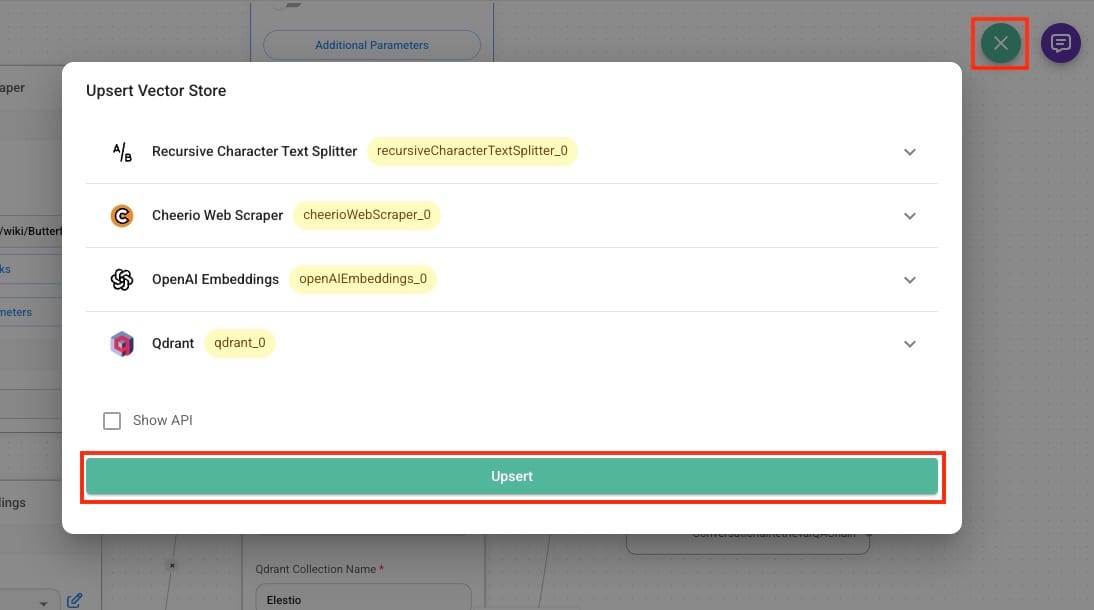
Additionally Upsert operation plays a crucial role in updating the vector database efficiently. When new documents are added or existing documents are modified, Qdrant supports upserting, which ensures that embeddings are updated without needing to clear the entire database. This allows for real-time updates and improved document retrieval accuracy. Upsert prevents outdated or redundant data from interfering with responses. You can click on the database icon on the top right side of the window and click on Upsert to start the process.
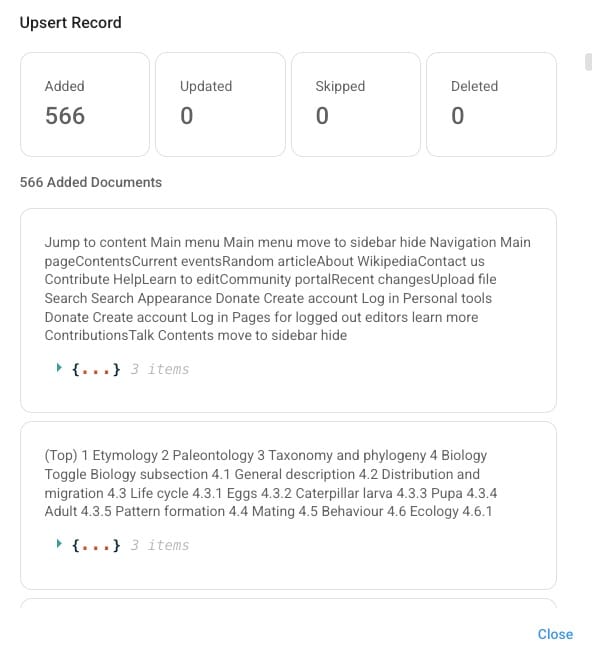
After this you will following response as recode where you can see all the information being processed and extracted from the flow chain before.
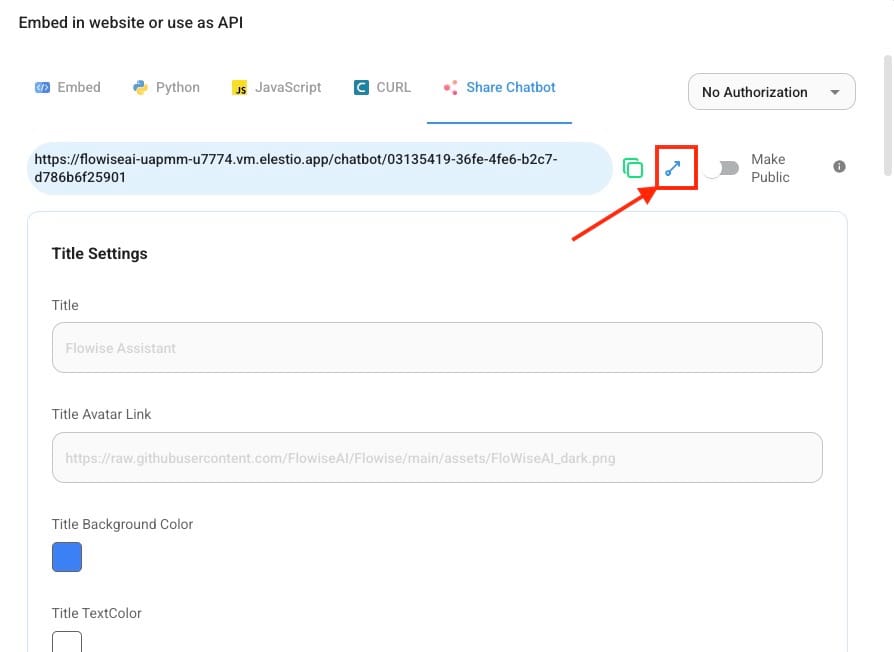
Now you can fine-tune it and use it by according to your requirement and then setup the form design as required and check the created QA System via button as shown below and make it publicly accessible as required.
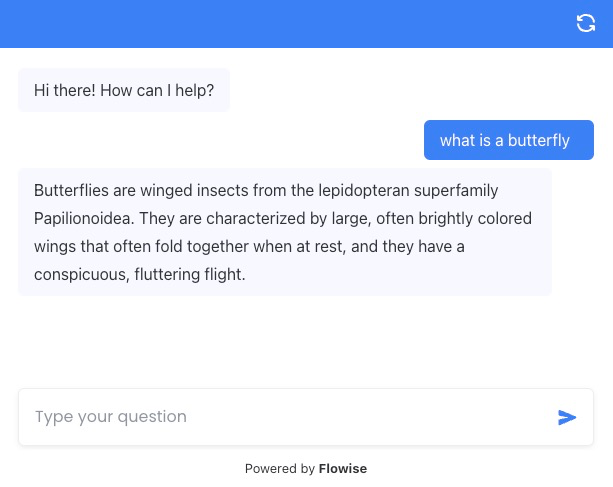
And now you can use your chat window for QnA related to butterflies
Thanks for Reading ❤️
Thank you so much for taking the time to read this blog! We hope it helped you understand how to build a document-based Q&A system using FlowiseAI, Qdrant, and OpenAI. By leveraging these tools, you can create an intelligent and efficient retrieval-augmented AI system that delivers accurate responses based on real-world data. Be sure to explore the official documentation for FlowiseAI, Qdrant, and OpenAI to dive deeper into their features and capabilities. If you’re ready to build your own Q&A system, start experimenting and fine-tuning the settings to achieve the best performance. See you in the next one! 👋
