
LiteLLM: Free Open Source Gateway to Manage All Your LLM Providers

As organizations adopt multiple large language model providers, complexity grows quickly. Different APIs, authentication schemes, rate limits, billing models, and response formats create operational overhead. Engineering teams end up writing and maintaining provider specific integration code instead of focusing on product value.
LiteLLM addresses this problem by acting as a unified gateway in front of all your LLM providers. It standardizes API calls, centralizes authentication, enforces usage controls, and provides observability across models. Instead of rewriting your application logic for each vendor, you integrate once with LiteLLM and route requests to any supported backend.
LiteLLM is free, open source, and designed to be infrastructure friendly. You can self host it, deploy it alongside your existing stack, and extend it as your needs evolve.
Watch our platform overview
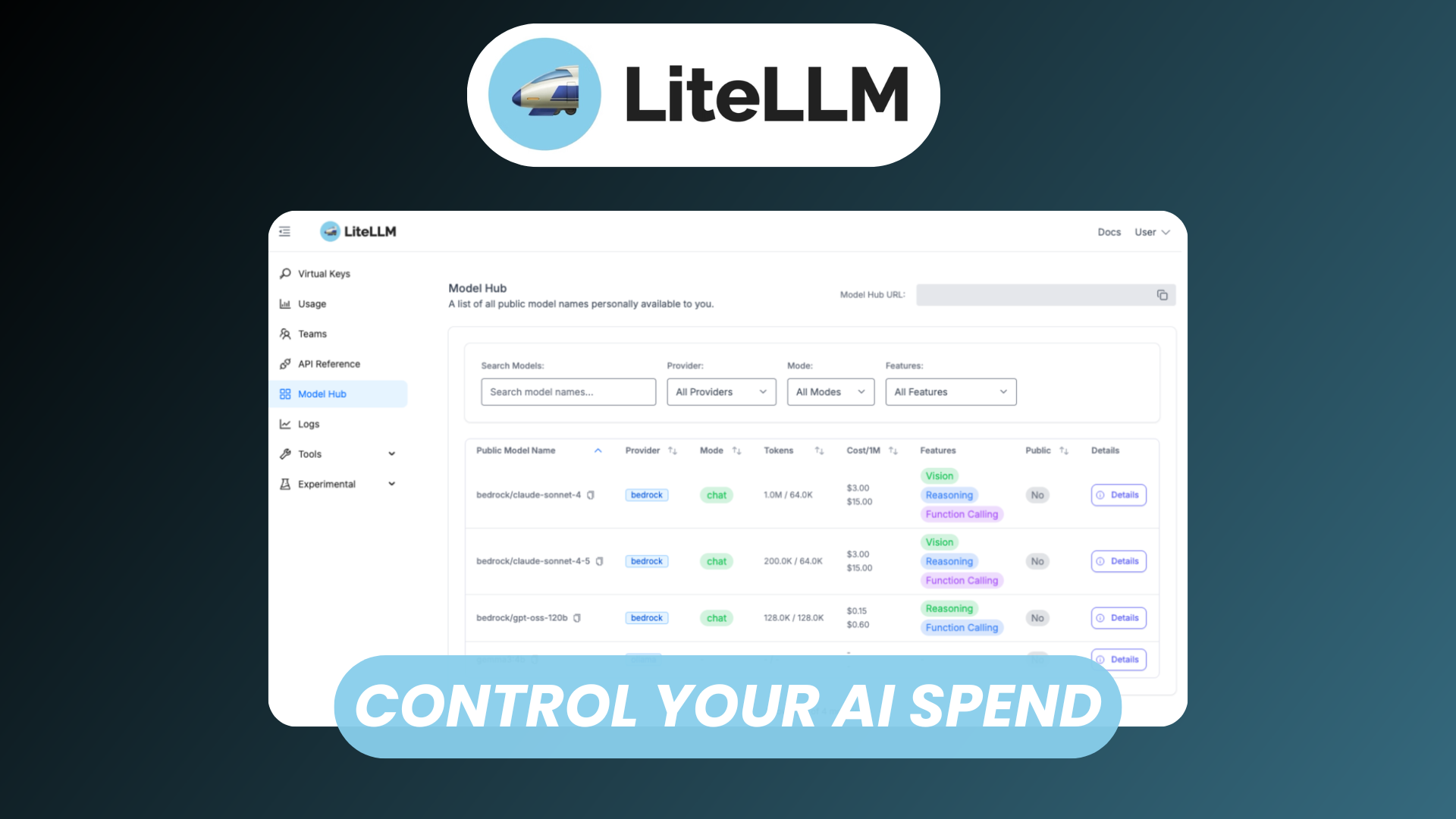
Models & Endpoints
One of LiteLLM’s core capabilities is abstracting multiple providers behind a single, consistent interface. Whether you use OpenAI compatible APIs, local models, or enterprise endpoints, LiteLLM normalizes the request and response flow.
Key capabilities include:
- Unified API surface across providers
- Model aliasing, for example mapping
gpt-4orproduction-chatto different backends - Fallback and routing rules between models
- Support for chat, completion, embeddings, and more
Instead of hard coding vendor logic, you define models and endpoints in configuration. Your application calls LiteLLM with a model name, and the gateway handles provider selection, authentication, and transformation.
This abstraction layer is especially valuable in environments where:
- You want redundancy across providers
- You need to compare performance and cost
- You plan to switch vendors without rewriting your codebase
Teams, Permissions, & Limits
Operational governance becomes critical once LLM usage expands beyond a small developer group. LiteLLM provides built in controls to manage access at scale.
With team based access controls, you can:
- Define teams such as Engineering, Support, or Research
- Assign models to specific teams
- Enforce per team rate limits and token quotas
- Track usage at the team level
This structure supports internal chargeback models and prevents accidental overspending. It also allows you to restrict access to higher cost models while enabling broader experimentation on lower cost ones.
Fine grained permissions ensure that sensitive models or endpoints are only accessible to authorized users or services.
Virtual Keys
Virtual keys are a powerful abstraction that decouple internal users from raw provider API keys.
Instead of distributing vendor credentials across applications and environments, you generate virtual keys within LiteLLM. These keys:
- Map to one or more underlying provider keys
- Enforce limits and policies
- Can be rotated or revoked centrally
- Provide traceable usage attribution
This approach improves security posture by reducing credential sprawl. It also simplifies key management when employees join or leave, or when services need temporary access.
Virtual keys act as programmable access tokens, giving you policy enforcement without exposing upstream secrets.
Playground
LiteLLM includes a built in playground to test models and prompts through the same gateway your production systems use.
The playground enables you to:
- Experiment with different models under a unified interface
- Compare outputs side by side
- Validate routing and fallback rules
- Test rate limits and permission configurations
Because it routes through the same gateway, results reflect real production behavior. This reduces discrepancies between experimentation and deployment.
For teams evaluating multiple providers, the playground accelerates model selection and tuning.
Usage Analytics
Cost visibility and performance monitoring are essential for sustainable LLM adoption. LiteLLM provides centralized analytics across all routed requests.
Usage analytics typically include:
- Token consumption by model, team, or key
- Request counts and latency metrics
- Error rates and failure patterns
- Estimated cost tracking
This consolidated view eliminates the need to log into multiple provider dashboards. It also enables proactive governance by identifying abnormal usage spikes or inefficient prompt patterns.
When combined with team level limits, analytics create a closed feedback loop between experimentation and cost control.
Agents & MCP
Modern LLM applications increasingly rely on agent architectures and tool calling patterns. LiteLLM supports advanced workflows, including agent style orchestration and integration with emerging protocols such as MCP.
By acting as the central gateway, LiteLLM can:
- Route agent requests to appropriate models
- Apply consistent authentication and logging
- Manage tool invocation policies
- Provide unified observability across multi step chains
For teams building autonomous workflows, this ensures that governance and monitoring remain intact even as complexity grows.
Whether you are orchestrating retrieval augmented generation pipelines or tool enabled agents, LiteLLM keeps the infrastructure layer standardized.
Conclusion
LiteLLM simplifies the operational complexity of working with multiple LLM providers. It unifies APIs, centralizes security, enforces limits, and delivers analytics in a single open source gateway.
For startups, it reduces vendor lock in and accelerates experimentation. For enterprises, it provides the governance, visibility, and policy controls required for production scale deployments.
By integrating once with LiteLLM, you gain the flexibility to route across providers, manage costs intelligently, and evolve your LLM strategy without constant rework.